
OnlineOrNot Diaries 10

Max Rozen (@RozenMD) / May 13, 2023
Another Saturday morning here in Toulouse, let's go into how OnlineOrNot went this fortnight.
In the last two weeks I:
- optimized a query that OnlineOrNot runs every 15 seconds, to run 90% faster
- decided to release a landing page for heartbeat checks before it was ready
- started an experiment with my onboarding flow
- refactored my AWS architecture for an 87.5% cost saving
Optimizing an expensive query
For OnlineOrNot I've opted to use RDS for simplicity, but as part of that simplicity, I don't get fancy lists of my most run queries with how long they take to run (a popular Heroku postgres feature) - unless you know something I don't? Let me know!
As a result, after two years of development, there are still unoptimized queries like this in my code:
// this isn't my actual code, but is a rough approximation of what it does
const checks = await sql`SELECT * FROM uptime_checks WHERE ready_to_run = TRUE`
// queue up the checks to run, then mark them as currently_checking
await Promise.all(checks.map((check)=>{
await sql`UPDATE uptime_checks SET currently_checking = TRUE WHERE id = ${check.id};`
}));
There's nothing fundamentally wrong with this approach, but each time you send a query to the database, there's a bit of overhead. Running over thousands of records in my case, this added up to spending 5 seconds updating records every 15 seconds.
The fix was to only send a single query to update the database:
// this isn't my actual code, but is a rough approximation of what it does
const checks = await sql`SELECT * FROM uptime_checks WHERE ready_to_run = TRUE`;
// queue up the checks to run, then mark them as currently_checking
await sql`UPDATE uptime_checks AS t SET "val"=v."val","msg"=v."msg"
FROM (VALUES${checks
.map((check) => `(${check.id}, TRUE)`)
.join(',')})
AS v("id","currently_checking")
WHERE v.id = t.id;`;
As a result, we now only spend 500ms updating the database, instead of 5000ms.
My incomplete landing page
I'm still working on heartbeat monitoring, and making it ready for general consumption. The thing is, starting marketing only when the feature is complete would be a mistake (this is what Coding Week, Marketing Week solves).
So as part of my marketing week this fortnight, I shipped an incomplete landing page with the intention of iterating on it, as I add features:
Experimenting with my onboarding
As I wrote about a month ago, I started running ads for OnlineOrNot. It's still unclear if it's paying off, so I'm keeping the ads running for now.
It was hard to figure out if ads were working, because folks were signing up, and immediately using the free tier, instead of starting a free trial. People do end up upgrading their subscription on the free tier, but it takes significantly longer than folks that use the paid version (it's a lot harder to see the value with half the features disabled).
So for the month of May, I've decided to see what happens if every user starts with a free trial. They'll be able to downgrade to the free tier for personal projects at any time, but the idea is to let them play with the fully-featured version of OnlineOrNot first, so they know what they're missing out on.
I'll let you know how this went in future diaries.
Refactoring my AWS architecture
As I (also) wrote just over a month ago, I keep two versions of OnlineOrNot running for redundancy: one on fly.io, and another on AWS. Due to network reliability issues with fly.io, I moved the majority of the workload back onto AWS.
However, I never took the time to refactor how my AWS app was setup, so it more-or-less looked the same for 18 months or so:
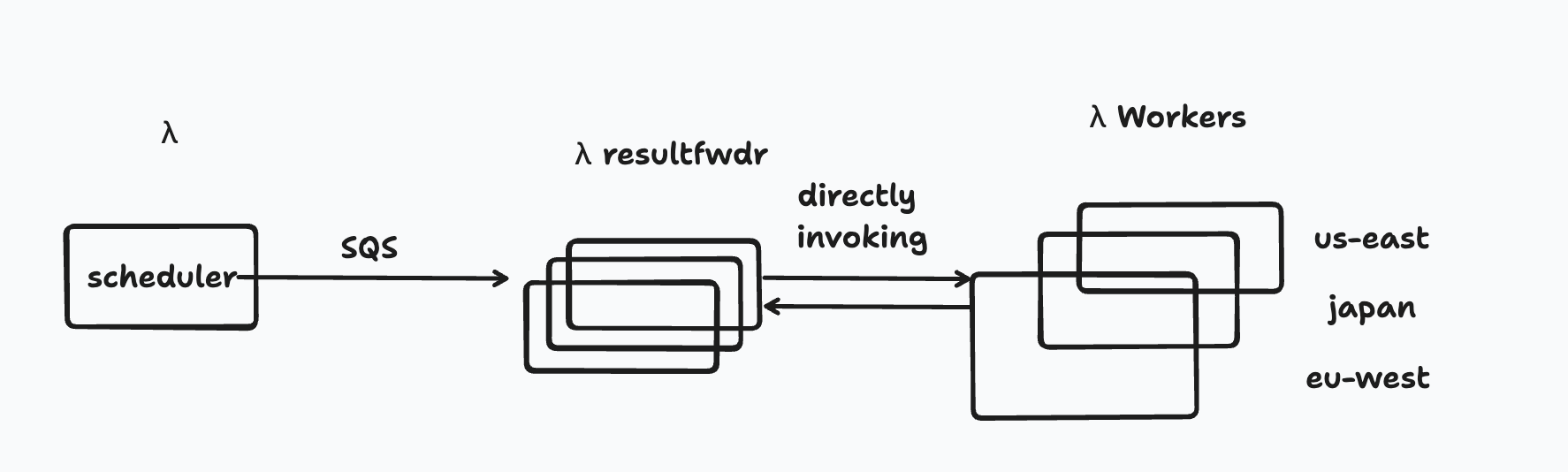
In short, a scheduler Lambda function runs every 15 seconds to find uptime checks it needs to queue up, sends the data over SQS to a set of resultfwdr Lambda functions which batch requests to the uptime checkers around the world. Only resultfwdr knows how to talk to my database, so I don't need to maintain thousands of connections to my database.
It's probably not obvious what's wrong with this architecture from the diagram, but the resultfwdr Lambdas have to start hundreds of uptime checker Lambdas simultaneously, and wait for them to finish before writing results to the database. Since this isn't Cloudflare Workers, I pay for the time AWS Lambda does nothing while waiting for the results to come back.
The main goal of this re-architecture was to minimize database load, as well as unnecessary AWS costs. So I decided to flip the architecture:
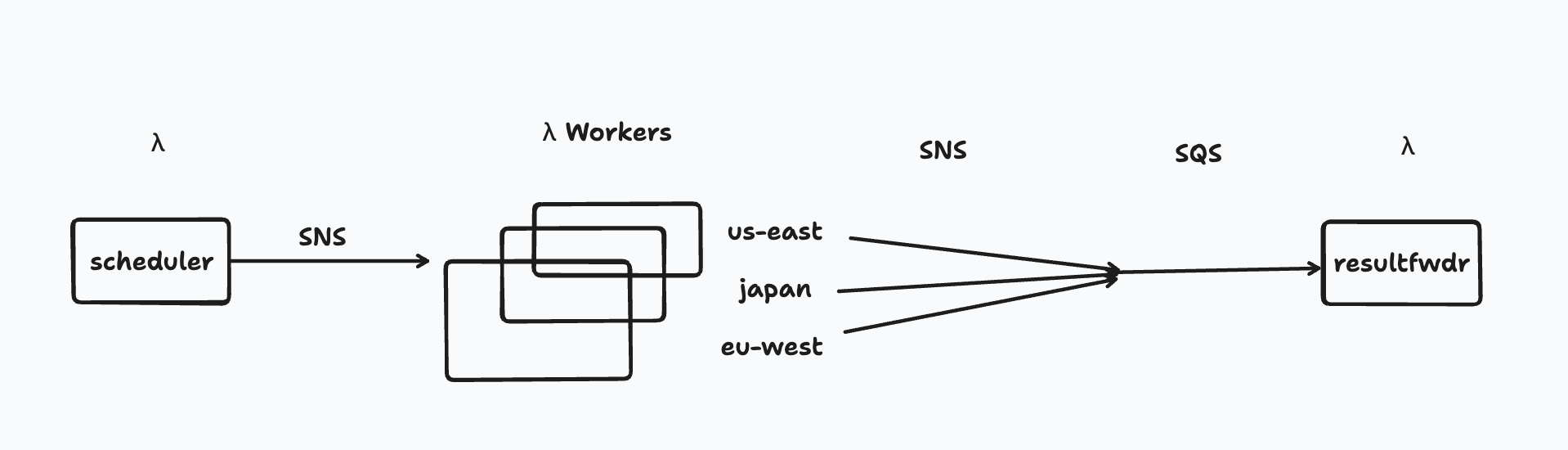
With this new architecture, there's no more waiting around for Workers to finish (apart from inside the uptime checks themselves), it's 87.5% cheaper to run the resultfwdr Lambda, and thanks to SNS, the Workers run their checks within milliseconds of being queued.