
OnlineOrNot Diaries 6

Max Rozen (@RozenMD) / March 31, 2023
Another Friday evening here in Toulouse, let's go into how OnlineOrNot went this week.
I was very close to not writing this week's diary as I felt it's probably too boring for most folks, but lets see how it goes.
This week was a coding week, and I spent most of it planning a new monitoring service for OnlineOrNot, migrating uptime checks back to AWS, and learning new things from other founders on Twitter.
Our upcoming monitoring service
So, there are 2880 30-second increments in a day. Assuming you can check each website within 30 seconds, you should be able to easily reach 2880 uptime checks per day.
For some reason, OnlineOrNot falls short. Not by much, it's about 1% off for the URLs I care enough about to monitor, but I'm still curious as to why it happens.
To help investigate the issue, I started building a hacky thing just for myself, before realizing several users have asked for this feature.
So this week I started designing a new monitoring service for OnlineOrNot: Heartbeat checks (also known as reverse monitoring). Heartbeat checks are where your service sends a request to a URL OnlineOrNot exposes only for you, and sends you an alert if you haven't sent a request within a given time period (if you over-check, OnlineOrNot will ignore the extra requests). There's also an advanced use-case where you send OnlineOrNot a request containing data, and it sends you an alert if the data fails against certain criteria, but that'll come later.
and back to AWS
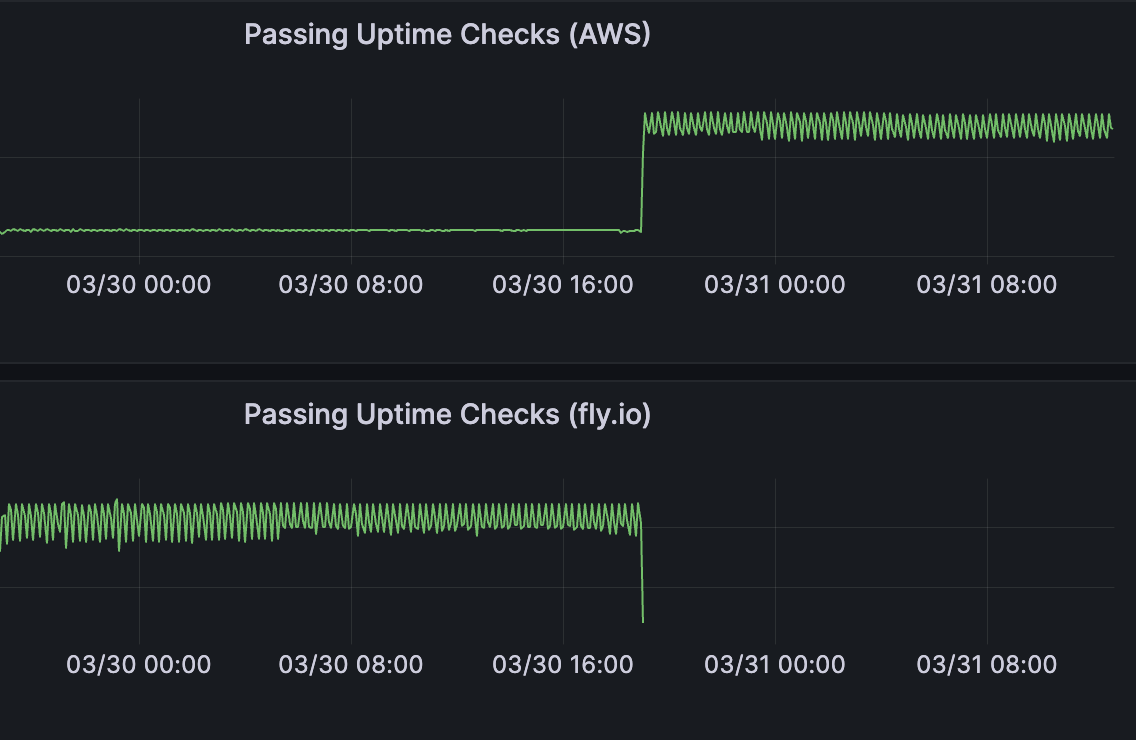
After a month of globally distributed uptime checks on fly.io, I'm cutting my losses and moving uptime checks back to AWS. The service itself is a joy to use (especially the iad region on the US east coast), but it's not stable enough to run uptime checks in each of their regions. It might make sense for running a web service, where a region's requests can failover to another region, but it just didn't work for me.
I found myself needing to run each check several times on fly.io, as well as backup checks on AWS AND Cloudflare to actually be sure an OnlineOrNot user's URL is actually down, rather than it being an issue with the VM I'm checking from.
Compare that to AWS, where 1 user out of 1305 has checks that consistently fail.
I'm not completely off fly.io though, my new architecture is a hybrid of fly.io and AWS, where a VM queues up checks to run in Redis every 15 seconds, another pulls checks from Redis, and runs the uptime check in a specific AWS region as needed.
Pricing Page Driven Development
I recently read Pricing Page Driven Development from Justin Duke, and it got me thinking about how I never really thought about expansion revenue. I was so excited about getting my first customers, that I was happy to keep the pricing page as-is.
Now that I have a decent number of paying customers, I'm beginning to notice patterns in the plans folks subscribe to, and realizing some changes need to be made to keep the business sustainable long-term. Of course, I don't plan on changing anything for my existing customers, but I'll be introducing a new "Freelancer" plan for solopreneurs to start with.